


Being mis-sold PPP. The failure of pharma's Predict, Pick, Plan model...

Most companies do it this way, mostly because it is the way they always did it. For any given asset, an ‘indication’ is picked, and then a path planned to that indication. The path will be linear, and typically follow the path of least resistance - start small, gain or lose confidence and hope the stars align for at least one drug per year. To have got there will have involved some prediction. Once predicted and picked, the planning will begin. Or, this is how they do it formally, at least - some companies use tacit knowledge and intuition to finesse their approach, but that’s not a sustainable model (I was reminded of the wonderful ‘eminence-based decision making vs evidence-based decision making’ last night).

The planning will involve collecting as much evidence as possible for that path, and only that path. If you have decided on a NASH indication, the fact that biomarker A vs B vs biomarker-less would have different costs, probabilities of success, timelines, commercial opportunities and challenges, will be inconvenient once you step out on the path. But that doesn’t mean they don’t still sit there as opportunities.
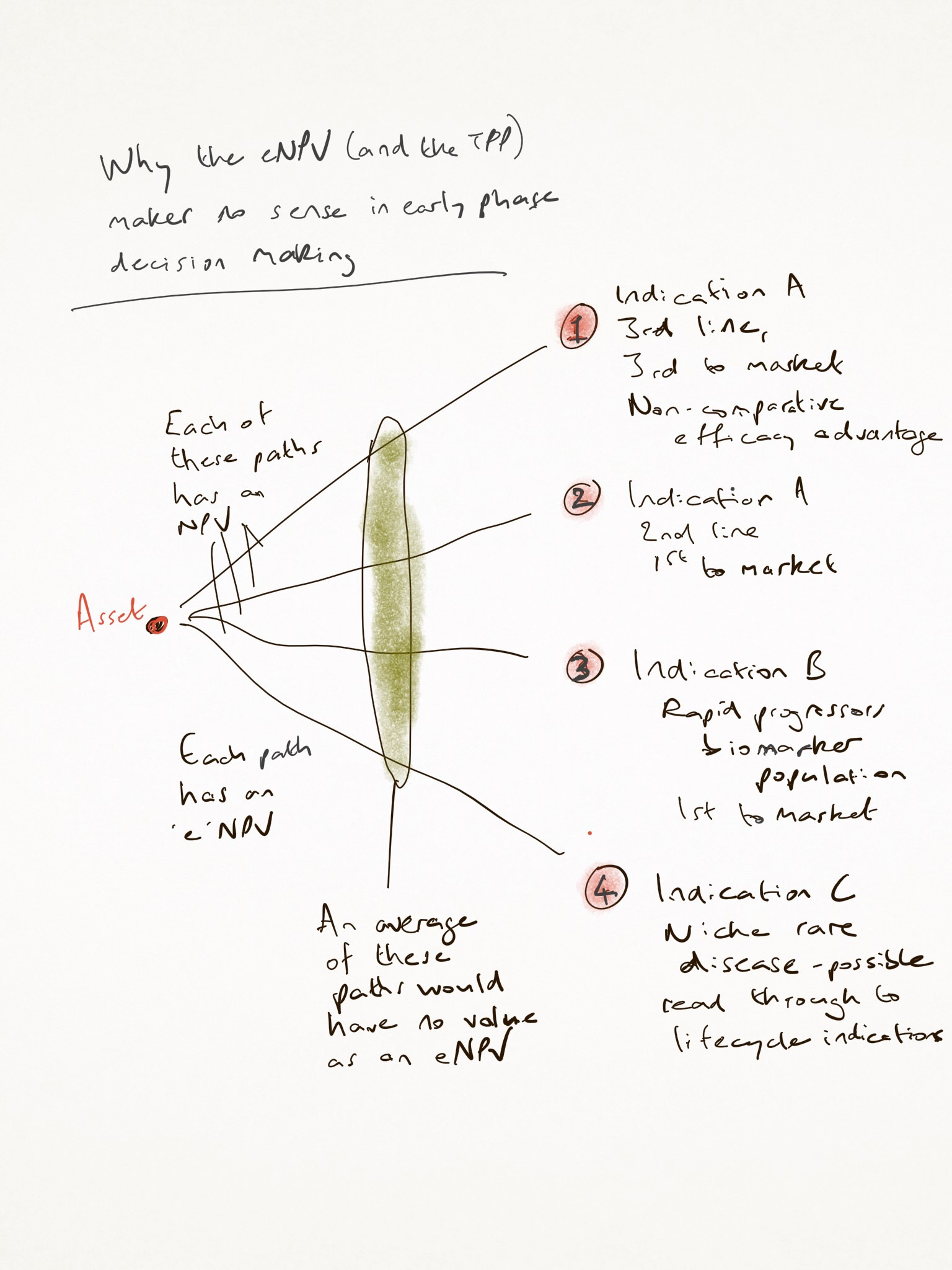
Here’s why that doesn't work: each of the potential paths has its own eNPV, which, however it is derived, is based on predictions that have impossibly wide confidence intervals, on probability assessments that cannot possibly be accurate, and on a destination which is too broad to be of value. Launching in ‘Multiple Myeloma’ is like choosing to go live in the USA - there’s a lot of decisions yet to make about where. So, your ‘Predict, Pick, Plan’ model is based on so many assumptions which are not ready for the decision you just made.

The opportunity for you and your team is not to try to be better at the task of prediction. Were you to improve your prediction power by 10x, it is unlikely at such an early stage that you could narrow your confidence intervals on your assumptions meaningfully. They’ll remain a statistics nightmare, given how many of them are independently important for a no-go. If we’re being honest this early, many of our lower bands for confidence will run close to zero, on things like safety signals, market potential, effect size and more. Those do not cancel each other out, but sit as hidden weak links in our decision chain, dragging the actual ‘e’ in the 'eNPV’ down to close to zero, however you do it. That is, if you are being honest, and addressing confidence intervals, which many choose not to be - it is too depressing to have one decision model and to see the truth laid bare in the simplest forecast models.
The eNPV can only be path-specific. And therefore, it is either done on one path, whose chooser cannot have known the opportunity of the other paths, or it is done across several, and averaged out, in which case it is meaningless.
Instead, the opportunity is not in improving your prediction power by 10x, it is to do two things really well. The first is easy: it is to accept (or, not ignore) that there is a wide range of potential destinations. And the second is even easier: it acknowledges that the probability changes along the path.

That is, the further back you make your predictions, the less useful your probability calculation will be. Even with only one path, a prediction made early will be less ‘accurate’ than one made later. This is true for every path you might examine. Your future self will be able to make better estimates than your current one can, because you will have newer and better evidence.
This, then, is your true opportunity: to create a learning approach that collects better evidence for your future self. If your goal is to increase the validity of your estimates in future, the value of the experiments you might do to those estimates is critical. Instead of a linear ‘let’s get a signal to go to phase III in this one path we chose in an invalid decision process’, you might choose to do experiments that would falsify your main hypothesis, or maintain your optionality to choose one of 5 or 10 different paths, validate an endpoint or a biomarker that will only have value to a future you, or evaluate a commercial scenario that will unlock a path that others hadn’t seen.
Experiments have a cost. Different experiments have different costs, but they also have different value to a future decision maker: evidential value, false positive/ false negative validity and more. Choosing to adopt a learning process means weighing the cost of finding out against the value of knowing. In a traditional linear approach, you will know only one thing, and even that will be uncertain. In an asymmetric learning approach, you can apply ‘decision economics’ - input cost vs output value. We are lucky in pharma that those output values really do have value. The acquisition cost of a drug at the beginning of phase I is not the same as at the beginning of phase II or phase III. Those among us who are able to conceive of better evidence processes (to address non-linear probability distributions) are, like the spheres in a Flatworld 2D world, already seeing things from above.
This mindset (the opportunity-seeking mindset) applies even in the presence of a single path to market. Your future self will be grateful for the evidence you chose to collect. It applies even more to the moment your future self sees that you bore in mind the range of potential destinations, so you can then pick your path from a set of options, rather than the only one you have evidence for. It is hard to imagine how you could be happy with absence of evidence for alternative paths, instead of evidence of absence.
Development is a decision science. It is not divorced from modern approaches (Taleb’s coverage of ergodicity is a good overview of the value of time amongst other things), but pharma R&D is largely beholden to a decision process based on premature specialisation and overconfident predictions. The alternative is to specialise as late as possible and to be aware of how we might make better predictions.
Hi, Thanks for sharing these helpful information, Keep posting and I'm looking forward to your next post